親密度の低い2字漢語と4字漢語短縮形のアクセントの生成
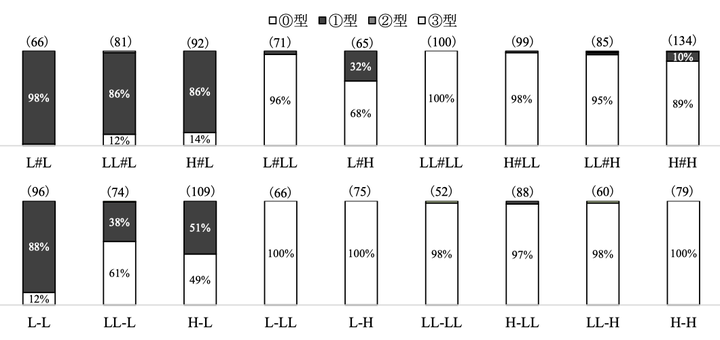 2字漢語と短縮語の調査結果
2字漢語と短縮語の調査結果
要旨
This paper investigates the accent distributions of two-character Sino-Japanese words and truncated Sino-Japanese compounds, using data from unfamiliar word read-aloud tasks participated by Tokyo metropolitan dialect speakers. The results show that the accent distribution of two-character Sino-Japanese words highly depends on the mora number of the second character, which coincides with previous studies examining accent dictionaries, and truncated Sino-Japanese compounds are generally more likely to be pronounced unaccented than two-character Sino-Japanese words. An analysis based on Stochastic Optimality Theory is proposed to explain different accent distributions and variations observed in the task results.
出版物
『音韻研究』第23号(pp. 35-44), 日本語音韻論学会編, 開拓社 (東京)