The Learnability of the Accentuation of Sino-Japanese Words and Loanwords: The Hidden Structure Problem
 GLA/EIPを利用した学習過程
GLA/EIPを利用した学習過程
要旨
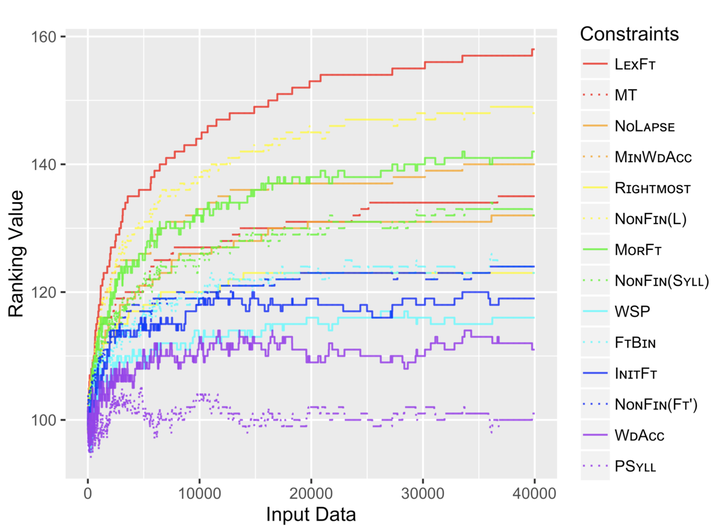
This paper analyzes the learnability of dominant accentual patterns of Sino-Japanese words and loanwords using the constraint ranking proposed by Li (2017) as the target grammar. Convergence results of computational simulations vary across algorithms and levels of inputs. Learning in the face of hidden structure, learners of Robust Interpretive Parsing (RIP; Tesar and Smolensky 2000) did not converge, indicating the failure to make full use of available probabilistic information. Instead, two novel parsing strategies proposed by Jarosz (2013) help to solve related problems of RIP, yielding significant improvements in performance even with the relatively complex target grammar.
出版物
『音韻研究』第21号 (pp. 31-40), 日本語音韻論学会編, 開拓社 (東京)